Scrapy 调试
通过 Shell 层层调试
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html- 然后用选择器筛选
IDE debug 启动 Shell
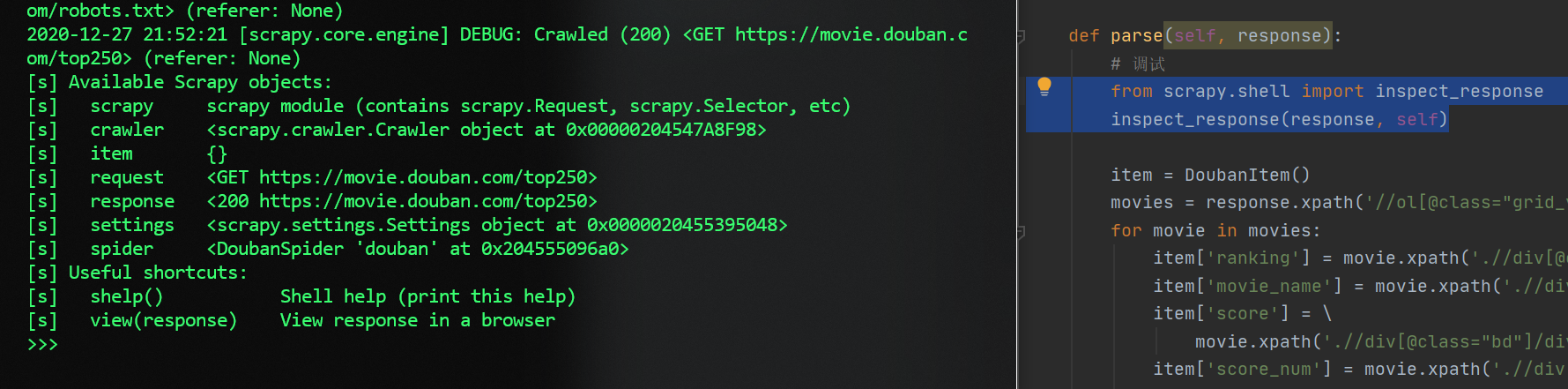
在代码中加入
1
2from scrapy.shell import inspect_response
inspect_response(response, self)scrapy crwal AAA启动项目- 然后项目执行到上面两句插入的位置的时候,就会启动 Shell
- 接着就在 Shell 里调试
直接在 IDE 里调试
- 新建文件写入
1
2
3
4
5from scrapy import cmdline
# douban 为要调试的文件名
name = 'douban'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
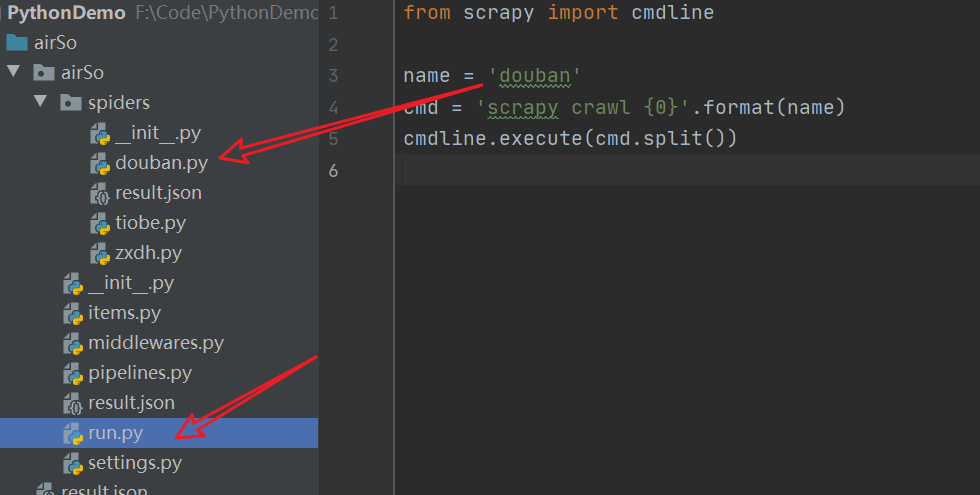
- 然后到要调试的文件里设置断点
- 最后回到上面新建的文件里面右键 debug 即可
设置请求头
- 有时候不设置请求头,会被拒绝访问 403
scrapy 有两种方式设置请求头,一种是在 settings.py 里配置
1
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
另一种是在函数里写
1
2
3
4
5class DoubanSpider(scrapy.Spider):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/53.0.2785.143 Safari/537.36',
}然后在 start_request()里调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com/top250']
# 把 这里的 start_urls 写在 start_requests() 里能执行更多操作,这里的只是简单的设置 url
# start_urls = ['http://movie.douban.com/top250/']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/53.0.2785.143 Safari/537.36',
}
# 这些方法参数 self 应该是指上面定义的那些变量
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
请求下一页,但没返回
- DEBUG: Filtered offsite request to
- 原因是 request 的地址和 allow_domain 里面的冲突,从而被过滤掉,可以停用过滤功能
1
2
3
4
5next_url = response.xpath('//span[@class="next"]/a/@href').extract_first()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url
-yield Request(next_url, headers=self.headers)
+yield Request(next_url, headers=self.headers, dont_filter=True)