CPU
- CPU(Central Processing Unit)[寄存器、控制器、运算器、时钟]
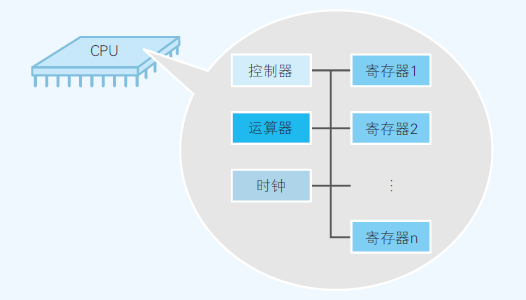
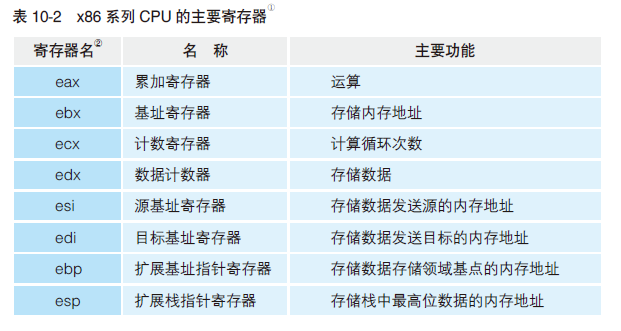
寄存器:暂存指令、数据
控制器:把内存上的指令、数据读入寄存器,并根据结果控制计算机
运算器:运算从内存读入寄存器的数据
时钟:发起计时
程序运行的过程:程序启动后,时钟开始计时,控制器从内存中读取指令和数据,运算器计算数据,控制器根据结果控制计算器
程序把寄存器作为对象来描述
- 汇编:将汇编语言转成机器语言;反汇编则反之
- 数据分为“用于运算的数据”和“表示内存地址的数据”
- 累加寄存器存放“用于运算的数据”
- 基址寄存器、变址寄存器存放“表示内存地址的数据”
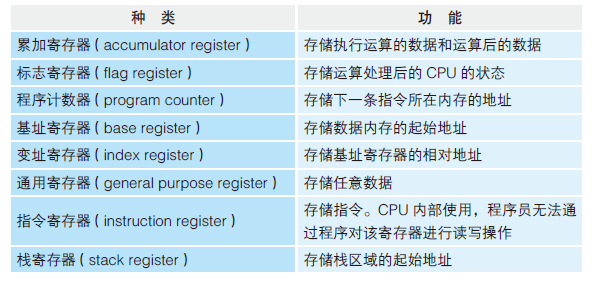
- 程序计数器、累加寄存器、标志寄存器、指令寄存器和栈寄存器都只有一个,其他寄存器一般有多个
- CPU是寄存器的集合体
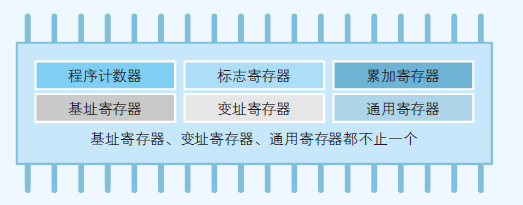
- 程序的流程由标志寄存器控制,标志寄存器保存当前流程执行的结果,然后选择路径(跳转指令)

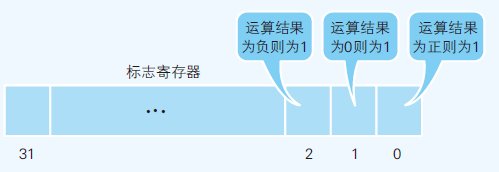

- 函数调用(call指令);return指令讲先前保存到栈中的地址设定到程序计数器中(这样函数就能返回开始调用时的位置)
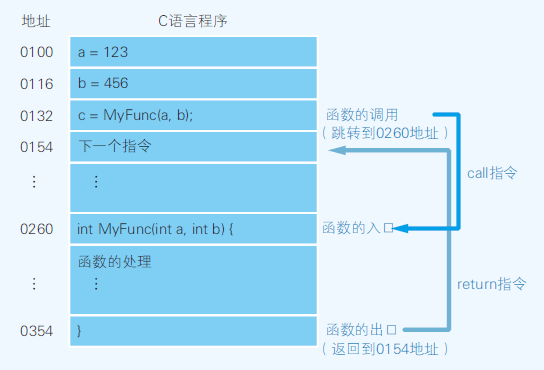
- 通过基址寄存器和变址寄存器来划分内存上的特定区域
- 机器语言指令主要类型:数据传送、运算、跳转、call/return
二进制表示数据
- 8位=1字节
- 集成电路(IC)所有引脚,只有直流电压0V或5V两个状态;所以IC一个引脚只能表示两个状态,决定了计算机数据只能采用二进制01来处理。
- 最小单位(bit)相当于二进制中的一位;bit(binary digit)
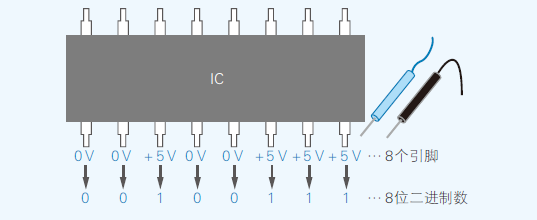
- 二进制的位数一般是8的倍数,8位二进制数=1个字节
- 字节是最基本的信息计量单位,位是最小单位,字节是基本单位
- 内存和磁盘都使用字节单位来存储和读写数据,使用位单位则无法读写数据。因此,字节是信息的基本单位
- 二进制 → 十进制

- 移位运算:<< 左移低位补0 ;

- 移位操作使最高位或最低位溢出的数字,直接丢弃
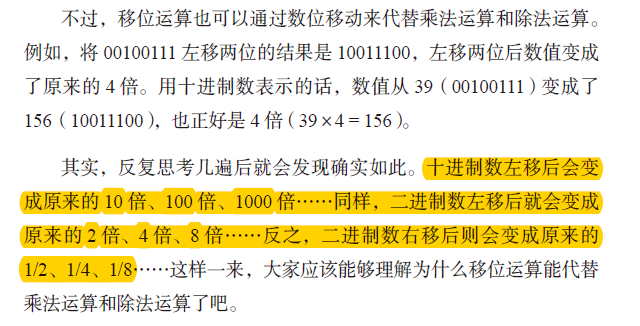
- 移位运算:>> 右移(逻辑、算数)[右移要区分逻辑位移和算术位移]
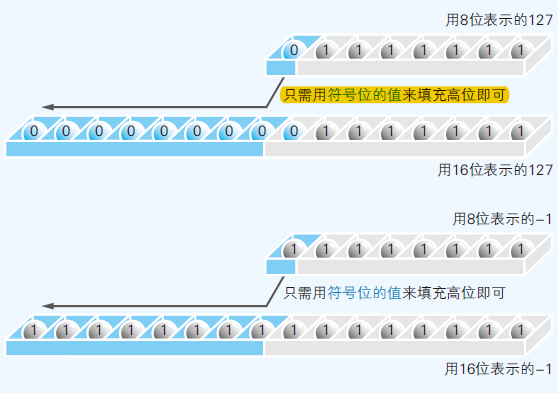
- 二进制表示负数:最高位为符号位;0正1负
- 1 二进制为 00000001 ;-1 二进制为 1111111
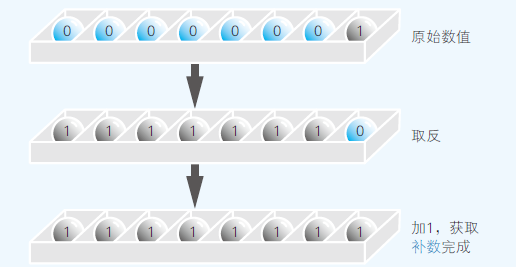
- 表示负数要用“二进制的补数”,补数:用正数来表示负数[比如:1-1 可以换种形式 1+(-1)]
- 获得补数:将二进制数位的数值全部取反,再加1
- 溢出的位,计算机直接忽略掉


- 0 划分为正数 ,所以负数要比正数多一个;各种数据类型都是负数多一个(比如 short -32768~32767)
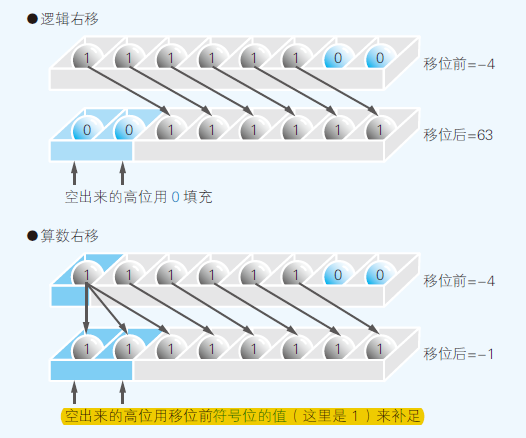
- 逻辑右移:当二进制数的值表示图形模式的时候,移位后需要在最高位补0
- 算数右移:当二进制数作为带符号的数值进行运算的时候,移位后要在最高位填充移位前符号位的值(0或1)
- 符号扩充:保持值不变的前提下将其转换成 16 位和 32 位的二进制数
- 非:0变1,1变9,取反
- 与:两个都为1,结果为1,其他情况为0
- 或:只要有1,结果就为1
- 异或:两个数不同,结果为1,其他0
- 0 false ; 1 true
小数运算出错的原因
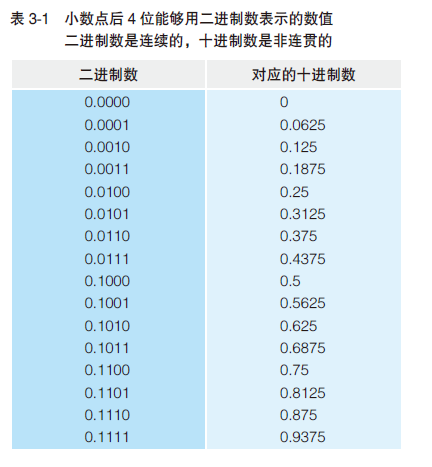
- 0.1累加100次不等于10,结果为10.000002
- 原因是有一些十进制的小数无法转换成二进制数(和0.3333···的三倍无法得出1是一个道理)
- 原因:(1)采用浮点数来处理小数;(2)位溢出
- 计算机无法直接处理循环小数
- 双精度浮点数类型64位,单精度浮点数类型用32位

- 回避策略:(1)无视,微小误差可以忽略;(2)把小数转成整数计算
内存
- 内存是 名为 内存集成电路 的电子元件
- 1K = 1024
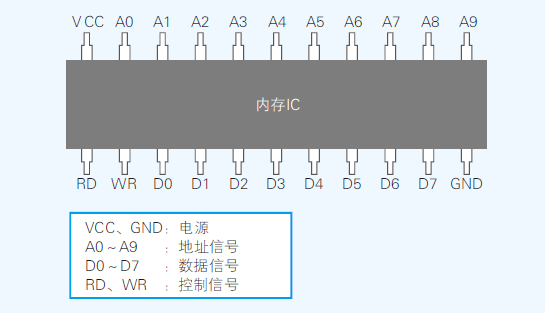
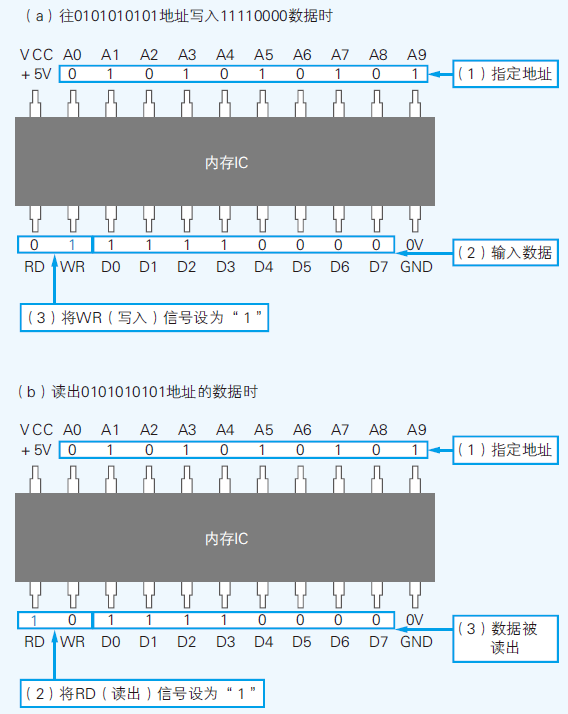
- +5V直流电压表示1,0V表示0
- D0~D7共八个,表示一次可以输入输出8位(1字节)数据
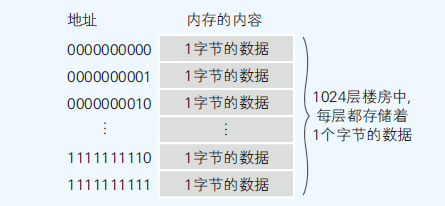
- A0~A9共十个,表示可以指定0000000000~1111111111(1024)地址
- 可以得出这个内存集成电路(IC)可以存储1024个1字节的数据,所以该内存IC的容量为1KB
- 现实中我们的内存IC会有更多的信号引脚,这样就能在一个内存IC中存储更多数据
- 内存IC的物理读写机制
- 内存逻辑模型
- 变量占用内存大小

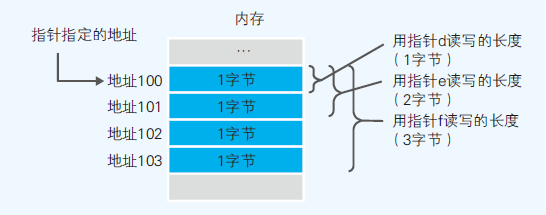
- 指针
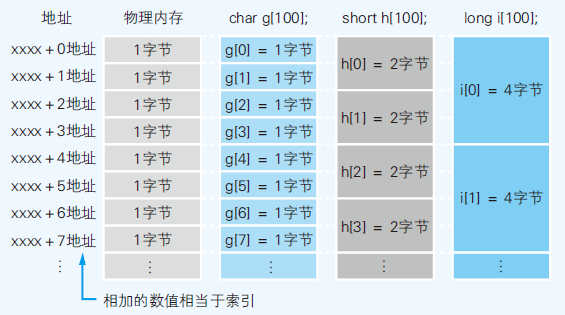
- 数组占用内存大小
磁盘
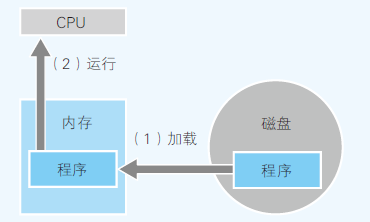
- 存储程序方式:程序保存在存储设备(磁盘、内存)中,通过有序地被读取出来实现运行
- 磁盘缓存,把已经在磁盘读取过的数据保存到内存,下次读取同样的数据就会从内存读取
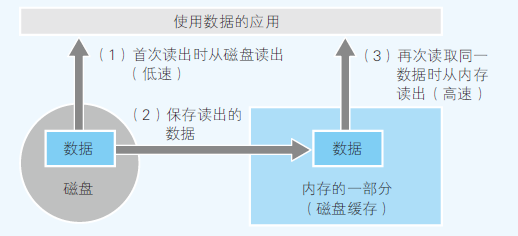
- 把低素设备的数据保存在高速设备中,需要时可以直接从告诉设备中读取
- Web浏览器也用到了此缓存方式,把从网络获取的数据暂时保存在磁盘中,需要时再读取
- 磁盘缓存:把内存的一部分当作磁盘使用(实际用的是内存)
- 虚拟内存:把磁盘的一部分当作内存使用(实际用的是磁盘)
- CPU只能执行加载到内存中的程序
- 虚拟内存虽说把磁盘当内存使用,但是实际正在运行的程序,这个时间点是必须存在于内存中的
- 所以为了实现虚拟内存,需要把 磁盘的虚拟内存里的内容 与 实际内存里的内容 进行置换
- 虚拟内存的方法:(1)分页式[Windows](2)分段式
- 分页式,把运行的程序按照一定大小的页(windows一般情况为 4KB )进行分割;以页为单位再磁盘和内存中置换,从磁盘读入内存(Page In),反之(Page Out)
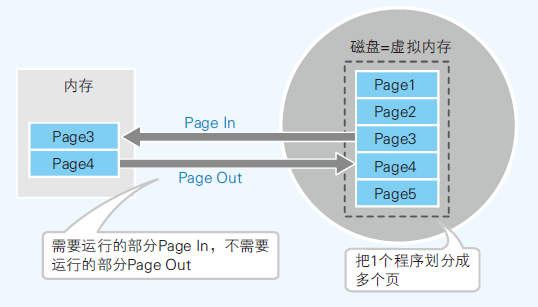
- 虚拟内存可以避免因内存不足导致的应用无法启动问题,从根本上解决还是要增加内存容量
- exe (executable)可执行,DLL (Dynamic Link Library)动态链接库
压缩数据
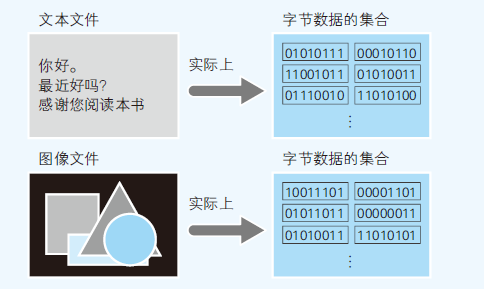
- 文件是字节数据的集合,在任何情况下,文件的字节数据都是连续的
- RLE算法(Run Length Encoding) [ 数据 X 重复次数 ]

- 哈夫曼算法 “出现频率高的字符用尽量少的位数编码来表示”
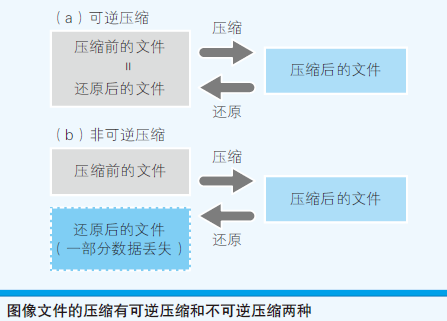
- 能够还原到压缩前状态的压缩成为可逆压缩,反之,非可逆压缩
运行环境
- 运行环境 = 操作系统 + 硬件
- CPU只能解释其自身固有的机器语言
- 不同的CPU能解释的机器语言的种类不同,例如:x86、MIPS、SPARC、PowerPC
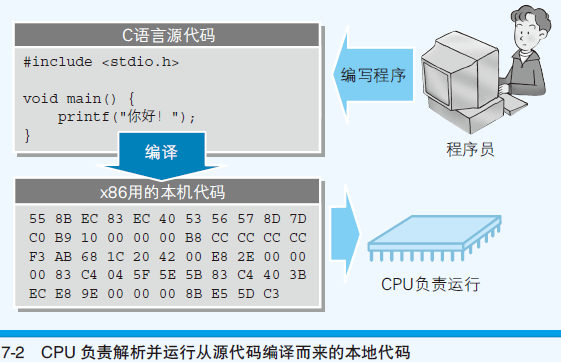
- 转换成 机器语言的程序 称为 本地代码
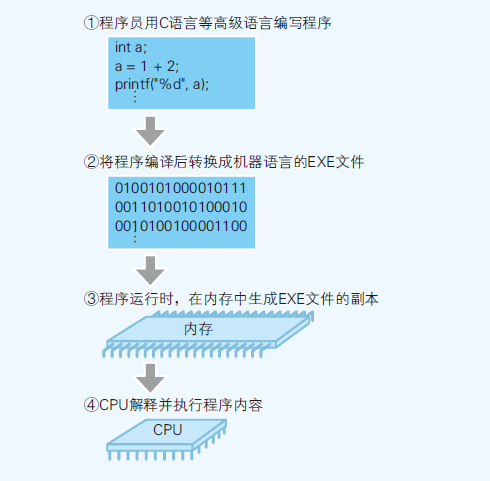
- 文本文件(源代码)在任何环境都能显示和编辑
- 源代码 → 编译 → 本地代码(本机CPU可解释的机器语言)
- MS-DOS(Microsoft Disk Operating System) → Windows
- Windows 克服了大多数的硬件差异问题
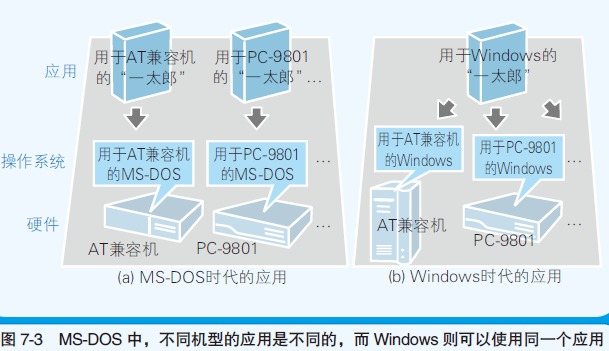
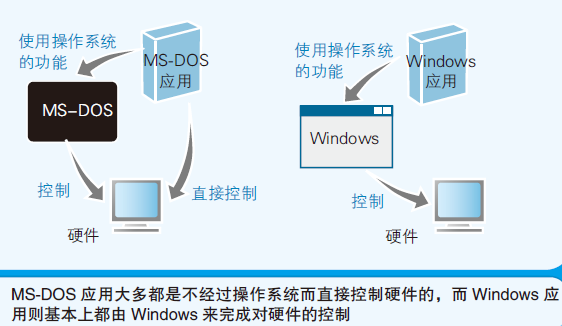
应用软件必须根据操作系统类型来开发,因为操作系统类型不同,应用程序向操作系统传递指令的途径(API [Application Programming interface])不同
移植:根据不同的运行环境来重新调整程序
- Java → 编译 → 字节码 → 运行 → Java虚拟机 → 转换 → 本地代码
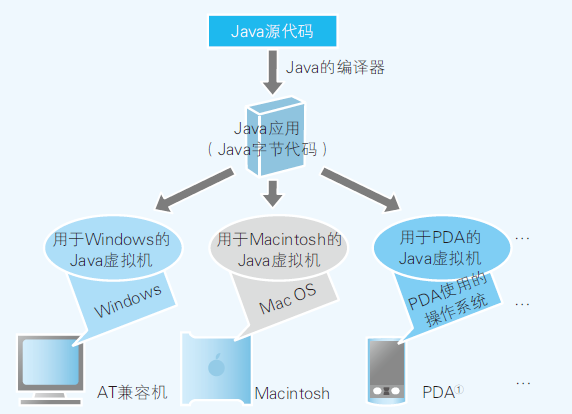
- 从操作系统方面来看,Java虚拟机是一个应用
- 从Java应用方面来看,Java虚拟机是运行环境
- 不同的Java虚拟机之间无法完整互换
- Java程序运行速度慢,因为Java虚拟机每次运行都需要把字节码转换成本地代码
- BIOS (Basic Input/Output System) , 启动 “引导程序”
- 引导程序 把在硬盘等记录的操作系统加载到内存中运行
编译过程
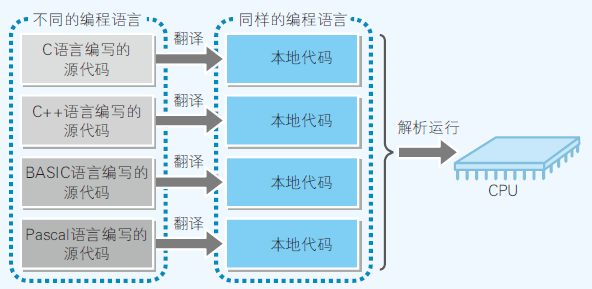
- Windows中exe文件的程序内容,使用的就是本地代码
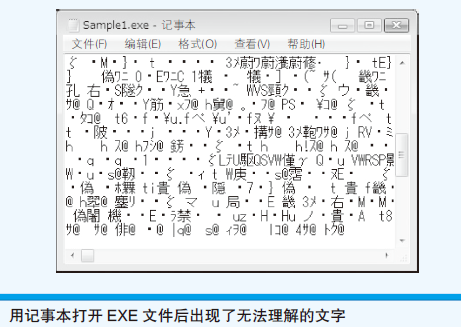
- Dump:把文件的内容,每个字节用2位十六进制数来表示
- 编译器:将高级语言写的源代码转换成本地代码的程序
- 每个高级语言都有它专用的编译器,C语言 —— C编译器
- CPU类型不同,本地代码的类型也不同;因此,编译器和 编程语言种类、CPU类型相关
- 例如:Pentium等x86系统CPU用的C编译器,和PowerPC的CPU用的C编译器是不同的
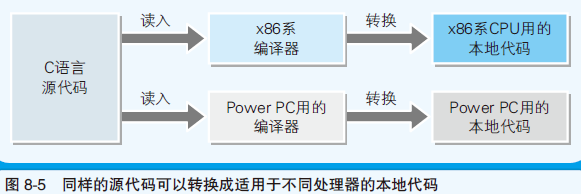
- 交叉编译器:生成和运行环境中的CPU不同的CPU所使用的本地代码;也就是说可以生成不同于本机CPU类型的本地代码

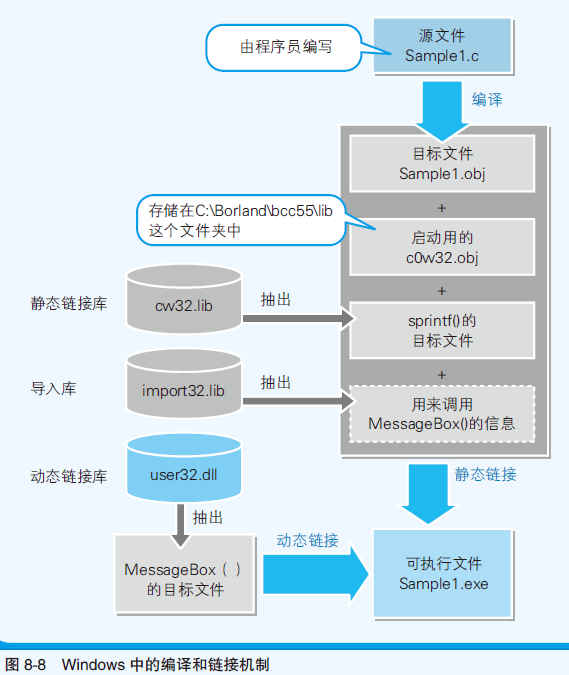
- 本地代码是无法直接运行的,需要得到可运行的exe文件,所以编译后还需要进行“链接”处理
- 把多个目标文件(.obj)结合,生成1个exe文件的处理就是链接
- 运行链接的程序 就称为 链接器
- 库文件:把多个目标文件集成到一个文件
- 内存泄漏:如果没有在程序中释放堆的内存空间,该内存空间会一直残留
内存泄漏如果一直存在,就有可能会造成内存不足从而导致宕机
编译器:在运行前对源代码进行解释处理
- 解释器:在运行时对源代码内容一行一行的进行解释处理
- 分割编译:将整个程序分成多个源代码来编写,然后分别进行编译,最后链接成一个exe文件
操作系统与应用
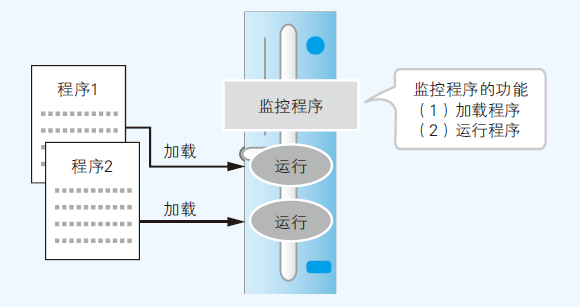
- 仅具有加载和运行功能的监控程序,是操作系统的原型
- 随着时代发展,渐渐的把同样处理的程序集成到监控程序中
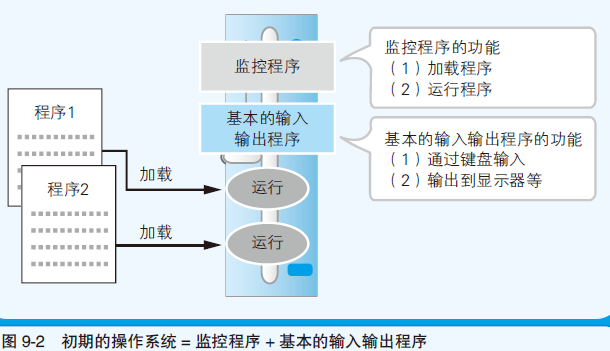
- 操作系统可以说是多个程序的集合体

- 各种应用只是在利用操作系统的功能而已
- 在操作系统诞生后,就不需要再编写直接控制硬件的程序了
- 这样制作软件应用逐渐与硬件分离,也就解耦了;无需再考虑硬件问题,硬件问题交给操作系统去处理
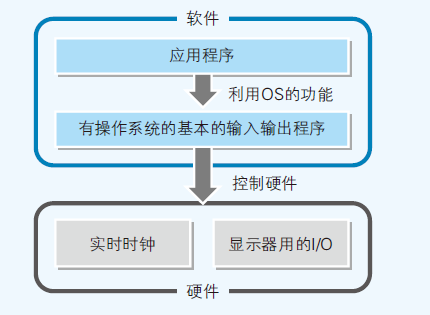
- 高级语言不依赖特定的操作系统,使用独自的函数名,然后在编译时将其转换成相应操作系统的系统调用
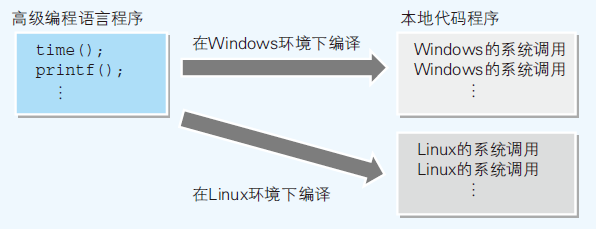
- 操作系统和高级语言能够使硬件抽象化
- 文件是操作系统对磁盘媒介空间的抽象化
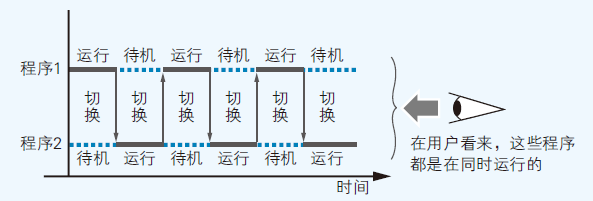
- 时钟分割:短时间间隔内,多个程序切换运行的方式;Windsows通过这种方式实现多任务功能
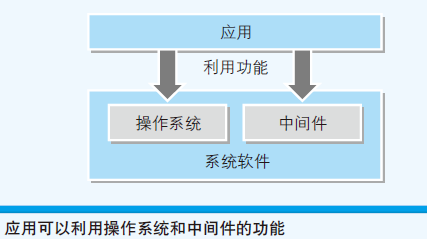
- 中间件:处于操作系统和应用的中间
- 系统软件:操作系统和中间件合合在一起
汇编
- 汇编语言的源文件 .asm (assembler)
- 汇编语言:使用助记符的编程语言
- 汇编语言源代码 → 用汇编器转换 → 本地代码
- 在将源代码转换成本地代码这个功能上,汇编器和编译器是同样的
- 汇编语言的编写的源代码,和本地代码一一对应
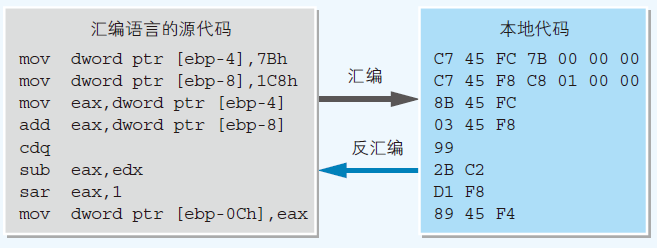
- C语言源代码 → 编译 → 本地代码 → 反汇编 → 汇编源代码
- 可以通过以上反汇编的方式,分析其代码内容;一般的逆向工程
- 汇编语言的源代码:由 (1)转换成本地代码的指令(2)针对汇编器的伪指令 构成
- 伪指令负责把程序的构造和汇编的方法指示给汇编器;伪指令本身是无法汇编转换成本地代码的


- 由伪指令 segment 和 ends 围起来的部分,是给构成程序的命令和数据的集合体加上一个名字而得到的,称为 段定义
- 在程序中,段定义指的是命令和数据等程序的集合体的意思
- 段定义是一个连续的内存空间
- 一个程序由多个段定义构成
- 源代码的开始位置,定义了 3 个名称分别为 _TEXT、_DATA、_BSS的段定义
- _TEXT 是指令的段定义
- _DATA 是被初始化(有初始值)的数据的段定义
- _BSS 是尚未初始化的数据的段定义
- group这一伪指令,表示的是把_BSS 和 _DATA 这两个段定义汇总为名为 DGROUP 的组
- group 指的是将源代码中不同的段定义在本地代码程序中整合为一个
- 围起 _AddNum 和 _MyFun 的 _TEXT segment 和 _TEXT ends,表示 _AddNum 和 _MyFunc 是属于 _TEXT 这一段定义的
- _AddNum proc 和 _AddNum endp 围起来的部分,以及 _MyFunc proc 和 MyFunc endp 围 起来的部分,分别表示 AddNum 函数和 MyFunc 函数的范围
- 伪指令 proc 和 endp 围起来的部分,表示的是 过程(procedure)的范围;在汇编语言中,这种相当于 C 语言的函数的形式称为过程
- 末尾的 end 伪指令,表示的是源代码的结束
- 在汇编语言中,一行表示对CPU的一个指令
- 汇编语言指令的语法结构是操作码 + 操作数 (也存在只有操作码没有操作数的指令)
- 操作码表示的是指令动作,操作数表示的是指令对象
- 能够使用何种形式的操作码,是由 CPU 的种类决定的
- 32 位 x86 系列 CPU 用的操作码
- 本地代码加载到内存后才能运行;内存中存储着构成本地代码的指令和数据
- CPU从内存中把指令和数据读出,然后由存储在CPU内部的寄存器来处理
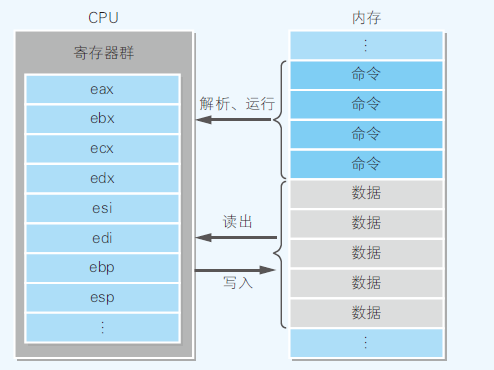
- 寄存器不仅有存储指令和数据的功能,也有运算的功能
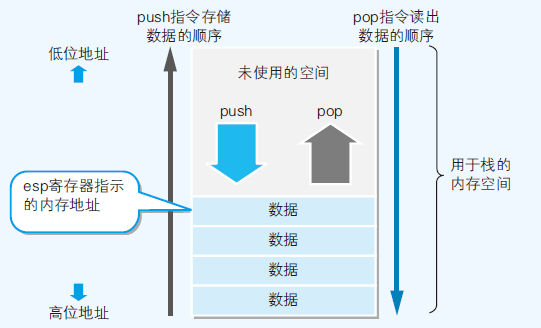
- LIFO (Last In First Out); push 入栈 , pop 出栈
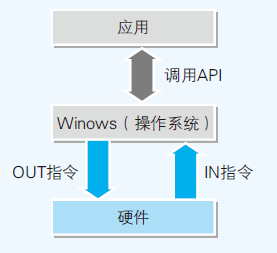
硬件控制
- 应用通过系统调用间接控制硬件
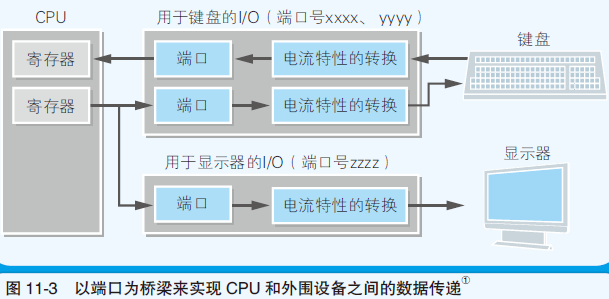
- 计算机主机中附带了用来连接外部设备的连接器,各个连接器内部都有用来交换主机和外设之间电流特性的IC,这些IC(集成电路)统称为 I/O 控制器
- 由于电压不同,数字信号和模拟信号的电流特征不同,主机和外设无法直接连接,I/O 控制器就是用来解决此类问题的
- I/O 控制器中有用于临时保存输入输出数据的内存,这个内存就是 端口 ,也称为 寄存器
- I/O 寄存器主要是用来临时存储数据的,CPU内部的寄存器是用来进行运算处理的
- 各端口之间通过 端口号 区分,也称为 I/O 地址
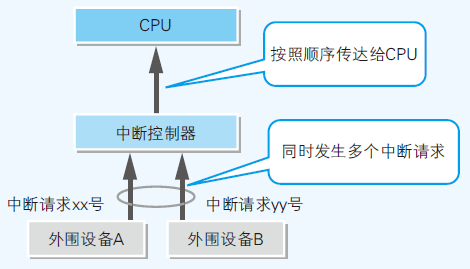
- IRQ(Interrupt Request) 中断请求
- IRQ 是用来暂停当前正在运行的程序,并跳转到其他程序运行的必要机制,该机制称为中断处理
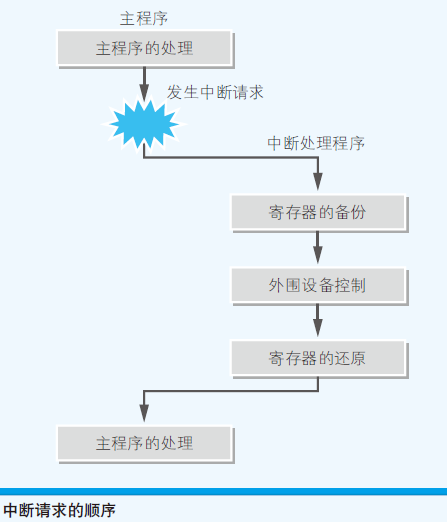
- DMA(Direct Memory Access):在不通过CPU的情况下,外围设备直接和主内存进行数据传送

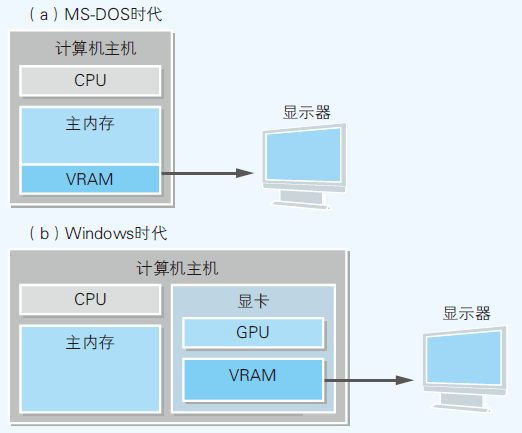
- VRAM(Video RAM):显示器中呈现的内容信息一直存储在某内存中